
Zpřístupnění archivu Českého rozhlasu pro sofistikované vyhledávání
Projekt řešený v rámci programu NAKI vyhlášeného Ministerstvem kultury
ČR v roce 2010
Identifikace projektu: DF11P01OVV013
Období řešení: 2011 - 2014
Řešitelské pracoviště: Technická univerzita v Liberci, Fakulta mechatoniky, informatiky
a mezioborových studií (FM) ve spolupráci s Fakultou přírodovědně-humanitní a pedagogickou (FP)
Řešitelský tým: 11 vědeckých a odborných pracovníků z Ústavu
informačních technologií a elektroniky a 3 vědečtí a odborní pracovníci Katedry českého jazyka a literatury
Vedoucí řešitel: prof. Ing. Jan Nouza, CSc.
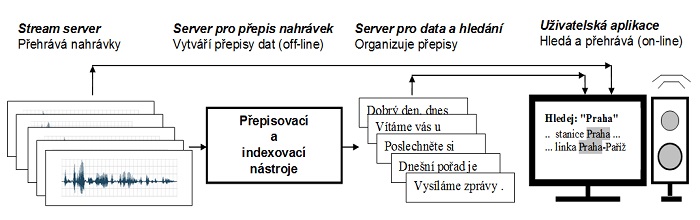
Základní schéma systému pro zpřístupnění archivu ČRo. Tvoří ho
- webová uživatelská aplikace, umožňující hledání a přehrávání nalezených záznamů
- stream server, poskytující přístup k audiozáznamů
- nástroje pro hromadný přepis a indexaci archivních záznamů
- databáze přepisů spolu s vyhledávacím serverem
Anotace projektu:
Archiv mluvených pořadů Českého rozhlasu je právem označován za jeden z klenotů kulturního dědictví ČR. Obsahuje totiž nejrozsáhlejší sbírku záznamů mluvené češtiny, unikátní svým objemem (v řádu stovek tisíc hodin nahrávek), obsahem (dennodenní komentáře k domácím i světovým událostem) i časovým rozpětím (více než 90 let nepřetržitého vysílání). Prvním krokem záchrany tohoto archivu byla digitalizace záznamů. Druhým krokem je jeho zpřístupnění pomocí nejmodernějších technologií zpracování řeči a textu. To je cílem tohoto projektu, jehož výsledkem je zpracování významné části archivu (zejména zpravodajských a publicistických pořadů) metodami počítačového přepisu řeči, uložení těchto přepisů doplněných o řadu detailních informací do databáze a umožnění neomezeného vyhledávání v této databázi způsobem obdobným jako u textových dokumentů (tzv. full-text search). Vytvořením komplexní softwarové technologie, zahrnující moduly zpracování audiosignálu archivních nahrávek, rozpoznávání řeči a řečníka, zaindexování přepisů do databáze, editoru a webového přehrávače, vznikl portál, který umožňuje nalezení libovolného slova či slovního spojení v archivu obsahujícím sto tisíc hodin záznamů, a to během několika sekund. Uživateli této unikátní technologie jsou především pracovníci Českého rozhlasu, jimž významným způsobem usnadňuje redakční práci. Potenciálními uživateli mohou být též historici, kteří tímto způsobem získají okamžitý a interaktivní přístup k archivním pramenům, či jazykovědci, pro něž bude takto zpřístupněný archiv zdrojem pro studie týkající se vývoje různých aspektů českého jazyka za posledních 90 let, a v neposlední řadě i vzdělávací instituce a odborná veřejnost.
Současný stav řešení projektu:
Práce na projektu byly dokončeny v roce v roce 2014, kdy byly zprovozněny všechny klíčové komponenty systému. Ve spolupráci s Českým rozhlasem (zejména s oddělením archivu ČRo) byly vytipovány pořady vhodné pro zpracování a tyto byly přeneseny na pracoviště řešitele. Jedná se o cca 100 000 hodin záznamů pokrývajících vysílání Českého a Československého rozhlasu od 20. let 20. století až do současnosti. V rámci řešení projektu byly nahrávky uloženy do obrovské zvukové databáze čítající několik stovek tisíc jednotlivých záznamů o celkovém objemu 6,5 terabajtů dat. Data jsou uložena roztříděna podle roku vysílání a dále podle stanic a pořadů. V rámci předzpracování a standardizace byla převedena do jednotného zvukového formátu. Následně byly aplikovány metody zpracování signálů (zaměřené na alespoň částečné potlačení šumu, komprese a dalších artefaktů spojených s jejich předchozích způsobem záznamu a uložení). Další kroky zpracování spočívaly v automatickém přepisu záznamů, v nichž byl nasazen systém rozpoznávání řeči vyvinutý na řešitelském pracovišti v posledních 15 letech a adaptovaný pro účely přepisu rozhlasových nahrávek, a to jak současných tak i historických. Jedním z důležitých kroků je identifikace dvou nejčastějších jazyků používaných v záznamech, a to češtiny a slovenštiny. V rámci projektu byl navržen a implementován modul, který tuto automatickou identifikaci umožňuje. Vlastní automatický přepis pak probíhá zvlášť pro segmenty, v nichž se mluví česky, a zvlášť pro slovensky mluvené části pořadů. Pro češtinu je používán slovník s cca 560 tisíci nejčastěji používanými slovy a slovními tvary, který byl v průběhu řešení projektu průběžně doplňován o slova specifická pro rozhlasové vysílání, a dále o nejčastější slova a vlastní jména používaná v předchozích historických obdobích (zejména v mezi roky 1945 až 1989). Rozšiřování slovníku a adaptace tzv. jazykového modelu představovalo samostatnou větev výzkumu, která si vyžádala velký objem pomocných prací spojených se získáváním a digitalizací historických textů (zejména archivních výtisků novin), které posloužily k nalezení historicky podmíněných slov a jejich kontextu. Modul určený pro přepis slovenštiny byl řešený podobným způsobem a pracuje se slovníkem s cca 310 tisíci slovy. Další úlohou řešenou v rámci projektu je identifikace mluvících osob podle hlasu tak, aby se u nejčastěji vyskytujících mluvčích mohlo objevit jejich jméno. Modul, který tuto úlohu realizuje, má ve své databázi cca 7300 osob, jejichž hlas je schopen identifikovat. Pro zlepšení přesnosti přepisu jsou využívány i další pomocné moduly, které se snaží identifikovat např. hudbu, a tu pak vyjmout z dalšího zpracování, nebo modul, který identifikuje telefonní řeč a pro její přepis pak používá speciálně adaptované komponenty přepisovacího systému.
Proces přepisu jednoho archivního záznamu je velmi složitou úlohou, na které se podílí několik vzájemně propojených modulů. I při nasazení nejrychlejších
a výpočetně optimalizovaných technologií (všechny byly vyvinuté na řešitelském pracovišti) trvá přepis jedné hodiny záznamu přibližně čtyřnásobek času. Zpracování
cílového objemu cca 100 tisíc hodin záznamů si vyžádalo přibližně 400 tisíc hodin výpočetního času. Toto by nebylo možné bez paralelního nasazení několika desítek
moderních počítačů, což bylo realizováno tak, že do přepisu bylo zapojeno několik počítačových učeben na TUL, které byly využívány v době mimo výuku.
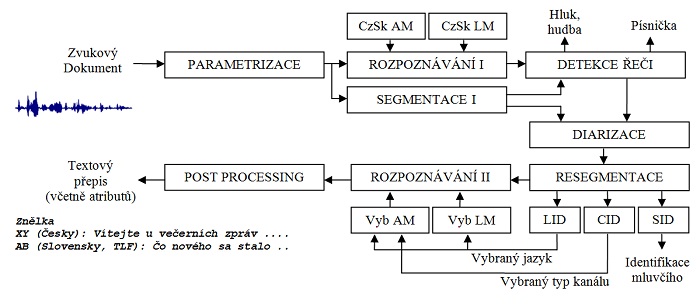
Schéma systémů a jeho modulů pro přepis archivních dokumentů - podrobnosti v článku
Hotové přepisy jsou následně uloženy do obrovské databáze, v níž je zvlášť zaindexováno každé rozpoznané slovo a to včetně přesné časové lokalizace (v řádu desítek milisekund) v rámci každého dokumentu. Tím je umožněno nejen nalezení hledaného slova, ale i okamžitý přístup k místu dokumentu, kde se slovo vyskytuje.
Z hlediska budoucího uživatele je pak nejdůležitější částí systému vyhledávací program. V něm je možné zadat hledané slovo či kombinaci slov, a dále podmínky pro hledání (např. časové období, název stanice či pořadu, jméno mluvící osoby). Po odeslání dotazu je během několik sekund vytvořen seznam pořadů, kde se hledaný výraz vyskytuje. Seznam je možné seřadit podle různých kritérií, např. podle relevance, času, apod. Uživatel má možnost rychle nahlédnout do té části přepisu, kde byl daný výraz detekován, a to pouhým najetím kurzoru na časovou značku označující výskyt slova na časové ose. Chce-li uživatel vidět kompletní přepis a slyšet konkrétní část záznamu, klikne na dané slovo a tím se dostane do režimu prohlížení konkrétního dokumentu. Zde může klikat na libovolná slova a poslouchat příslušné části dokumentu - viz video.
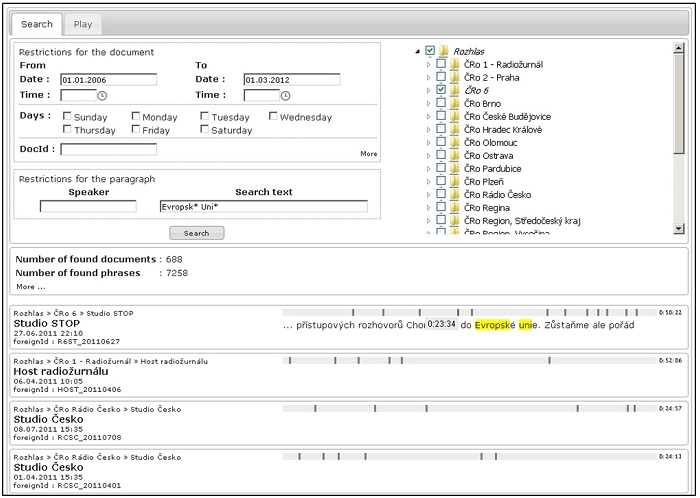
Uživatelské rozhraní pro vyhledávání v archivu
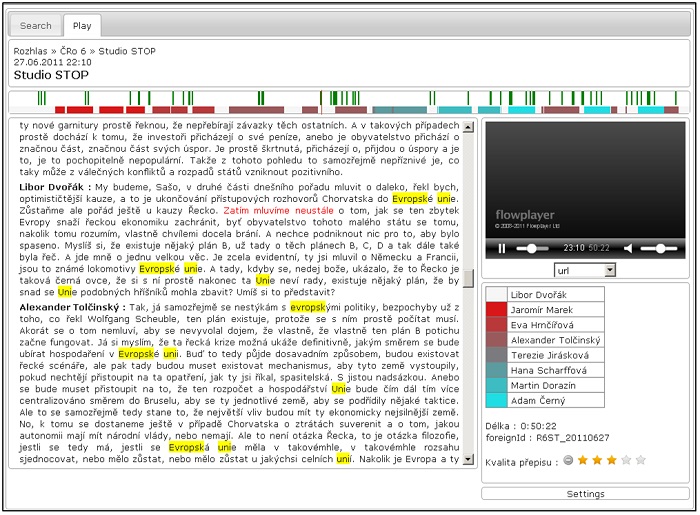
Vyhledávací systém v režimu přehrávání konkrétního pořadu s vyznačenými nalezenými slovy
Během čtyřleté práce na projektu se podařilo významným způsobem zvýšit přesnost automatického přepisu, a to jak nasazením nejmodernějších metod rozpoznávání řeči, tak i tím, že se systém postupně učil a adaptoval na specifický zvukový i řečový charakter archivních záznamů. Přesnost přepisů přesto závisí na mnoha faktorech, z nichž nejdůležitější jsou
- způsob mluvené řeči (na jedné straně mluva profesionálních redaktorů, na opačné straně pak spontánní nespisovné promluvy náhodně oslovených osob na ulici),
- kvalita záznamu (na jedné straně moderní zvukotěsné studio vybavené kvalitním mikrofonem, na druhé straně pak např. zahraniční telefonát, sportovní přenos nebo třeba 80 let starý archivní záznam),
- způsob uložení dat v rozhlasovém archivu (na jedné straně kvalitní bezeztrátově komprimovaný soubor, na druhé straně pak záznam slyšitelně zkreslený nevhodně zvolenou ztrátovou kompresí)
- téma a doba vzniku konkrétního zvukového příspěvku (příspěvky, které obsahují velmi specifické, odborné či historicky podmíněné výrazy a slovní spojení mají mnohem menší šanci na kvalitní přepis, protože slova v nich obsažená nemusí být součástí slovníku, byť se v tomto projektu jedná o dosud největší slovník použitý kdy pro automatický přepis češtiny (s cca 560 tisíci slovy).
Rozsáhlé testování ukázalo, že nejvyšší průměrné přesnosti (kolem 90 %) je dosahováno u zpravodajských pořadů, u nichž je kvalita záznamu i styl mluvené řeči na nejvyšší úrovni. Horší výsledky přepisů se zákonitě objevují u o záznamů rozhovorů (kvůli častějšímu používání nespisovné mluvy a rovněž v úsecích, kdy si osoby "skáčou do řeči") , u telefonátů, sportovních přenosů a zejména u nekvalitně nahraných či uložených historických záznamů. U těchto audiozáznamů může být přesnost přepisu významně nižší a ani nejmodernější metody rozpoznávání řeči ji zatím neumějí výrazně zlepšit. Podrobná analýza chyb však ukázala, že mnohé nepřesnosti přepisu souvisí s chybným rozpoznáním (záměnou, vynecháním nebo vložením) krátkých slov, nejčastěji spojek a předložek, případně s chybně rozpoznanou koncovkou slova. Tento typ chyb naštěstí nemá kritický dopad na hlavní cíl projektu, tedy na umožnění vyhledávání, neboť funkční či pomocná slova (např. spojky či předložky) nebývají předmětem vyhledávání. Vliv špatně rozpoznané (a v mnoha případech i špatně vyslovené) koncovky se dá úspěšně eliminovat tím, že při vyhledávání použije hvězdička na místě koncovky (např. Evropsk* uni*).
Vybrané statistiky ilustrující obrovský objem provedených prací a přepsaných dat:
|
Ukazatel |
Hodnota |
|
Celkový objem přepsaných a zaindexovaných dat (hodiny) |
102.953 |
|
Celkový objem přepsaných a zaindexovaných dat (terabajty) |
6,5 |
|
Počet stanic ČRo, jejichž pořady byly přepsány a zaindexovány |
20 |
|
Počet různých pořadů, které byly přepsány a zaindexovány |
326 |
|
Počet audiodokumentů, které byly přepsány a zaindexovány |
213.453 |
|
Počet všech zaindexovaných slov |
469.976.314 |
|
Počet různých zaindexovaných slov |
790.530 |
|
Počet různých zaindexovaných mluvčích |
7.293 |
|
Celkový datový objem vytvořených a zaindexovaných textů (GB) |
95 |
|
Celkový počet PC podílejících se na přepisech |
49 |
|
Odhad celkového objemu výpočetního času za 4 roky (hodiny) |
1.500.000 |
Publikace vzniklé v rámci řešení projektu:
2014
- Nouza, J., Červa, P., Žďánský, J., Blavka, K., Boháč, M., Silovský, J., Chaloupka, J., Kuchařová, M., Šeps, L., Málek, J., Rott, M.: Speech-To-Text Technology to Transcribe and Disclose 100,000+ Hours of Bilingual Documents from Historical Czech and Czechoslovak Radio Archive, In: Proceedings of the 15th Annual Conference of the International Speech Communication Association (INTERSPEECH 2014), Singapore, pp. 964-968, ISSN 2308-457X, 2014
- Chaloupka, J., Nouza, J., Málek, J., Silovský, J.: Phone Speech Detection and Recognition in the Task of Historical Radio Broadcast Transcription, In: Proc. of Telecommunications and Signal Processing (TSP) conference, Berlin, Germany, pp. 433 – 436, ISBN: 978-80-214-4983-1, ISSN 1805-5435, 2014
- Silovský, J., Nouza, J., Kuchařová, M.: Search for speaker identity in historical oral archives, In: An International Journal Multimedia Tools and Applications, pp. 1-20, ISSN 1380-7501, July 2014, DOI 10.1007/s11042-014-2067-2
- Boháč, M., Blavka, K.: Using Suprasegmental Information in Recognized Speech Punctuation Completion, In 17th International Conference, TSD 2014, Springer-Verlag Berlin Heidelberg, pp. 555-562, ISSN 0302-9743, ISBN 978-331910815-5, DOI: 10.1007/978-3-319-10816-2_50, 2014
- Škodová, S., Kuchařová, M.: Mluvené slovo v pořadech Českého rozhlasu. SALi. 2014, roč. 5, č.1, s. 141–143. ISSN 1804-3240. Recenzovaný časopis Studie z aplikované lingvistiky (SALi)
- Kuchařová M.; Škodová, S.; Šeps, L.; Boháč, M. :Study on Phrases Used for Semi-Automatic Text-Based Speakers’ Names Extraction in the Czech Radio Broadcasts News. Text, Speech and Dialogue Lecture Notes in Computer Science. In Lecture Notes in Computer Science, Springer Verlag Berlin, Volume 8655, 2014, pp 416-423. ISBN 978-3-319-10815-5. Online ISBN 978-3-319-10816-2. Series ISSN 0302-9743. SCOPUS ISI.
- Škodová, S. Použití interpunkce v automatických přepisech mluveného slova. Didaktické studie. Monotematické číslo Syntax v teorii a praxi jazykového vyučování. 2013, roč. 5, č. 2, s. 99–111. ISSN 1804-1221. Recenzovaný časopis
- Pacovská, J. Диалог на языке тела и психосоматическа фразеология. In Journal of Psycholinguistics, Institute of linguistics of Russian academy of sciences / Moscow institute of linguistics : Moscow, 2 (18), 2013, pp 46-53. ISSN 2077-5911. (В перечене российских рецензируемых научных журналов ВАК No 641 Подписной индекс Роспечати 37152
- Nouza, J., Cerva, P., Silovsky, J.: Adding Controlled Amount of Noise to Improve Recognition of Compressed and Spectrally Distorted Speech, In International Conference on Acoustics, Speech, and Signal Processing Mobile App - ICASSP 2013, Vencouver, Canada, pp. 8046-8050, ISBN 978-1-4799-0356-6,2013
- Nouza, J., Cerva, P., Silovsky, J.: Dealing with Bilingualism in Automatic Transcription of Historical Archive of Czech Radio, In ICIAP 2013 - International Workshop on Multimedia for Cultural Heritage MM4CH, Springer-Verlag Berlin Heidelber, Italy, pp. 238-246, ISBN 978-3-642-41189-2, 2013
- Chaloupka, J., Nouza, J., Kucharova, M.: Using Different Types of Multimedia Resources to Train System for Automatic Transcription of Czech Historical Oral Archives, In ICIAP 2013 - International Workshop on Multimedia for Cultural Heritage MM4CH, Springer-Verlag Berlin Heidelber, Italy, pp. 228-237, ISBN 978-3-642-41189-2, 2013
- Chaloupka, J., Nouza, J., Cerva, P., Malek, J.: Downdating lexicon and language model for automatic transcription of Czech historical spoken documents, In 16th International Conference, TSD 2013, Springer-Verlag Berlin Heidelberg, pp. 201-208, ISSN 0302-9743, 2013
- Kucharova, M., Skodova, S., Seps, L., Labus, V., Nouza, J., Bohac, M.: On the Quantitative and Qualitative Speech Changes of the Czech Radio Broadcast News within Years 1969-2005, In 16th International Conference, TSD 2013, Springer-Verlag Berlin Heidelberg, pp. 360-368, ISSN 0302-9743, 2013
- Lábus, V.: Nisa, or Nysa? Acta Onomastica LIII, pp. 207-218, ISSN 1211-4413, 2013
- Nouza, J., Blavka, K., Bohac, M., Cerva, P., Zdansky, J., Silovsky, J. and Prazak, J.: Voice Technology to Enable Sophisticated Access to Historical Audio Archive of the Czech Radio. In: Proc. of Multimedia for Cultural Heritage, vol. 247, Springer, Berlin Heidelberg, ISBN 978-3-642-27977-5, ISSN 1865-0929, pp. 27-38, 2012
- Nouza, J., Blavka, K., Cerva, P., Zdansky, J., Silovsky, J., Bohac, M. and Prazak, J.: Making Czech Historical Radio Archive Accessible and Searchable for Wide Public. In: Journal of Multimedia, vol. 7, no. 2, Academy Publisher, pp. 159 – 169, ISSN 1796-2048, 2012
- Nouza, J., Blavka, K., Žďánský, J., Červa, P, Silovský, J, Boháč, M., Chaloupka, J., Kuchařová, M., Šeps, L.: Large-Scale Processing, Indexing and Search System for Czech Audio-Visual Cultural Heritage Archives. In: Proc. of IEEE conf. on Multimedia Signal Processing (MMSP), Banff, Canada, pp. 337-342, ISBN 978-146734572-9, 2012
- Boháč, M., Blavka, K., Kuchařová, M., Škodová, S. : Post-processing of the Recognized Speech for Web Presentation of Large Audio Archive, In: Proc. of Telecommunications and Signal Processing (TSP) conference, Prague, pp. 441 – 445, ISBN: 978-1-4673-1117-5, 2012
- Boháč, M., Nouza, J., Blavka K.: Investigation on Most Frequent Errors in Large-Scale Speech Recognition Applications. In: Proc. of Text, Speech and Dialogue (TSD). Springer Verlag Berlin Heidelberg, Series LNCS 7499, pp. 520-527, ISBN 978-3-642-32789-6, ISSN 0302-9743, 2012
- Silovský, J., Červa, P., Žďánský, J., Nouza J.: Study on Integration of Speaker Diarization with Speaker Adaptive Speech Recognition for Broadcast Transcription. In: Proc. of Interspeech 2012, Portland, USA, 2012
- Škodová, S., Kuchařová, M., Šeps, L.: Discretion of Speech Units for the Text Post-processing Phase of Automatic Transcription (in the Czech Language), In: Proc. of Text, Speech and Dialogue (TSD). Springer Verlag Berlin Heidelberg, Series LNCS 7499, pp. 446-455, ISBN 978-3-642-32789-6, ISSN 0302-9743, 2012
- Lábus, V.: Atyp v cihle aneb O jednom progresivním způsobu neologizace. In: Naše řeč, no. 4., pp. 187-197, ISSN 0027-8203, 2012
- Bohac, M., Blavka, K.: Automatic segmentation and annotation of audio archive documents, In proc. of. 10th IEEE International workshop on Electronics, Control, Measurement and Signals (ECMS 2011), June 1-3 2011, Liberec, Czech Republic, pp. 61 - 66, ISBN 978-1-61284-395-7, 2011
- Nouza, J., Blavka, K., Bohac, M., Cerva, P., Zdansky, J., Silovsky, J., Prazak, J.: Voice technology to enable sophisticated access to historical Czech Radio audio archive, In proc. of International Workshop on Multimedia for Cultural Heritage (MM4CH 2011), Springer-Verlag, volume CCIS 247, May 3 2011, Modena, Italy, pp.27–38, 2011
- Cerva, P., Palecek, K., Silovsky, J., Nouza, J.: Using Unsupervised Feature-Based Speaker Adaptation for Improved Transcription of Spoken Archives, In proc. of the 12th Annual Conference of the International Speech Communication Association (Interspeech 2011), Florence, Italy 2011, pp. 2565 - 2568, ISSN 1990-9772, 2011
- Nouza, J., Blavka, K., Bohac, Kucharova, M, Zdansky, J., Seps, L., Prazak J.: System for Transcribing and Accessing Historical Archive of Czech Radio. In Proc. of 5th Language & Technology conference (LTC 2011), Poznan, Poland, pp. 585, November 2011
Realizované aplikované výstupy projektu:
Hlavní výstup R - unikátní softwarová technologická platforma pro přepisy archivů historických i současných pořadů ČRo a jejich zpřístupnění pomocí webu je již v provozu. Jedná se o skutečně komplexní a rozsáhlou platformu zahrnují několik výkonných serverů a využívající též univerzitní výpočetní klastr, kterou řídí několik desítek softwarových modulů. Pro přístup do vyhledávací aplikace je po dohodě s ČRo vyžadována registrace.
Pracovníci ČRo využívají tuto aplikaci již od poloviny roku 2014 a použili ji např. při vyhledávání dobových dokumentů pro aktuálně běžící program Znovu89, který mapuje dění v roce 1989 prostřednictvím archivních nahrávek z dané doby.
Celá platforma se skládá z několika desítek vzájemně propojených modulů, z nichž některé bylo nutné vyvinout specificky pro tento projekt.
Jedná se moduly:
R – Softwarový modul pro rozpoznávání a přepis slovenštiny v archivech mluvené řeči. Ten řeší detekci a následně i přepis slovensky mluvených částí
dokumentů.
R – Softwarový modul pro rozpoznávání osob podle hlasu v archivních záznamech. Jedná o modul, který využívá předem naučené
akustické profily cca 7300 osob a snaží se je na základě toho identifikovat.
R – Prezentační webová aplikace pro testování přístupu k archivu. Jedná
o interaktivní webovou aplikaci. V ní lze zvolit podmínky pro vyhledávání a získat přehled nalezených
dokumentů. Kliknutím na dokument nebo na jeho časovou osu s vyznačením pozice hledaného slova se lze dostat do režimu, kdy je nalezená část přehrávána. Tato aplikace má řadu možností, jak
ji efektivně využívat, které jsou popsány ve stručném manuálu v záložce.
R – Editor přepisů pořízených systémem pro automatické rozpoznávání řeči.
Editor umožňuje uživatelům (se zvláštním oprávněním, nejčastěji redaktorům ČRo) efektivním způsobem opravovat vybrané části přepisů. Editor lze vyvolat ve výše uvedené aplikaci
ve chvíli, kdy je zobrazen a přehráván konkrétní pořad.