
Vícejazyčný on-line systém pro přepis televizních a rozhlasových pořadů
V rámci projektů MULTILINMEDIA a DEEPSPOT byla vytvořena komplexní softwarová platforma, která umožňuje v reálném čase monitorovat a analyzovat nejen tisková ale především audio-vizuální média (zejména televizní a rozhlasové stanice) v různých jazycích. Hlavním inovačním jádrem platformy jsou technologie automatického přepisu řeči zvládající rozpoznávání mluvené řeči v celkem sedmi jazycích, a to v češtině a slovenštině (tyto jazyky byly ve velké míře řešeny již v před započetím projektu) a dále v polštině, chorvatštině, srbštině, slovinštině a ruštině. Tyto jazyky byly vybrány proto, že reprezentují populačně, ekonomicky a strategicky významnou část slovanských zemí, do nichž společnost Newton Media, a.s., v souladu se svou vizí rozvoje směřuje své aktivity. Kromě zvládnutí automatického přepisu v těchto jazycích se projekt zaměřoval také na další vylepšování a zefektivňování metod zpracování psaného a mluveného jazyka s ohledem na nejnovější poznatky v oboru strojového učení, zejména na využití umělých neuronových sítí. V posledním roce řešení projektu byly všechny průběžně vyvíjené metody a moduly integrovány do funkčního celku, který byl průběžně testován, prezentován budoucím klientům a do určité míry nasazován ve zkušebním provozu.
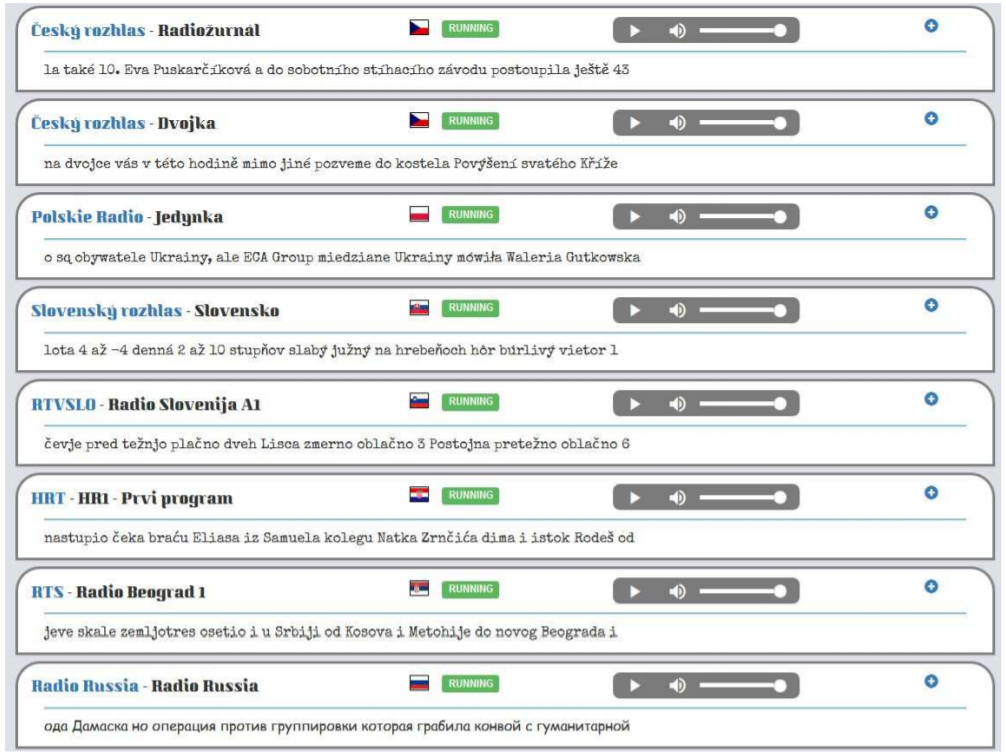
(screenshot pořízen dne 4.1.2018 v 14:05 hodin)
Navržená Platforma je modulární, takže ji lze aplikovat podle různých potřeb domácích i zahraničních klientů. Její velkou výhodou je to, že ji lze provozovat na počítačovém cloudu a paralelně tak zpracovávat desítky úloh, které se mohou lišit zdroji multimediálních dat, použitými jazyky a aplikačními slovníky, požadavky na rychlost zpracování, apod. V souladu se současným trendem poskytování podobných služeb (jak je tomu např. u velkým firem typu Google, Microsoft, Amazon) se počítá s tím, že platforma bude provozována v cloudu spravovaném firmou Newton Media a.s. a domácí i zahraniční zákazníci k ní budou přistupovat prostřednictvím Internetu. Znamená to tedy např., že si určí stanice či další zdroje, které chtějí monitorovat a pomocí webových technologií si budou odebírat průběžné či souhrnné výsledky. Takto to již bylo s úspěchem vyzkoušeno v testovacím provozu u zákazníků v Česku, Polsku, Chorvatsku a Slovinsku.
Výsledný systém si můžete prohlédnout zde
Vícejazyčný on-line systém vznikl díky podpoře dvou velkých TAČR výzkumných projektů "MultiLinMedia" a "DeepSpot".
Více informací:
- Mateju, L., Cerva, P., Zdansky, J.: An Approach to Online Speaker Change Point Detection Using DNNs and WFSTs, INTERSPEECH, pp. 649-653, 2019.
- Malek, J., Zdansky, J., Cerva, P.: Robust Recognition of Speech with Background Music in Acoustically Under-Resourced Scenarios, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5624-5628, 2018.
- Mateju, L., Cerva, P., Zdansky, J., Safarik, R.: Using Deep Neural Networks for Identification of Slavic Languages from Acoustic Signal, INTERSPEECH, pp. 1803-1807, 2018.
- Malek, J., Zdansky, J., Cerva, P.: Robust Automatic Recognition of Speech with background music, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5210-5214, 2017.
- Mateju, L., Cerva, P., Zdansky, J., Malek, J.: Speech Activity Detection in online broadcast transcription using Deep Neural Networks and Weighted Finite State Transducers, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5460-5464, 2017.
- Nouza, J., Safarik, R., Cerva, P.: ASR for South Slavic Languages Developed in Almost Automated Way, INTERSPEECH, pp. 3868-3872, 2016.
- Seps, L., Malek, J., Cerva, P., Nouza, J.: Investigation of deep neural networks for robust recognition of nonlinearly distorted speech, INTERSPEECH, pp. 363-367, 2014.
- Cerva, P., Silovsky, J., Zdansky, J., Nouza, J., Seps, L.: Speaker-adaptive speech recognition using speaker diarization for improved transcription of large spoken archives, Speech Communication, 55, pp. 1033-1046, 2013.