
Real-time transcription of radio streams in various languages
 During the last two decades, we have been developing automatic speech recognition (ASR) systems for various applications and languages. They use state-of-the-art technologies, mainly deep neural networks, at several levels including speech/non-speech or speaker change-point detection, acoustic modelling, etc.
During the last two decades, we have been developing automatic speech recognition (ASR) systems for various applications and languages. They use state-of-the-art technologies, mainly deep neural networks, at several levels including speech/non-speech or speaker change-point detection, acoustic modelling, etc.
NewtonDictate – software for fluent dictation to PC
 The software for fluent dictation was developed by in collaboration with the Newton Technologies company, which distributes it under name NewtonDictate. This software is aimed at general public, and at professions, like lawyers, doctors and people from the media domain. It comes with several types of lexicons. The general-purpose one is the largest and it contains 500K words recently. More information about the software NewtonDictate is in Newton Technologies company, which is the exclusive distributor.
The software for fluent dictation was developed by in collaboration with the Newton Technologies company, which distributes it under name NewtonDictate. This software is aimed at general public, and at professions, like lawyers, doctors and people from the media domain. It comes with several types of lexicons. The general-purpose one is the largest and it contains 500K words recently. More information about the software NewtonDictate is in Newton Technologies company, which is the exclusive distributor.
 The main goal of this project was to develop a complex platform that can transcribe, index and make searchable the historical archive of Czech and Czechoslovak Radio. The archive covers 90 years of public broadcasting and contains hundreds of thousands audio documents. The developed modular platform employs our LVCSR system that has to cope with 2 related languages: Czech and Slovak.
The main goal of this project was to develop a complex platform that can transcribe, index and make searchable the historical archive of Czech and Czechoslovak Radio. The archive covers 90 years of public broadcasting and contains hundreds of thousands audio documents. The developed modular platform employs our LVCSR system that has to cope with 2 related languages: Czech and Slovak.
ATT (Audio Transcription Toolkit)
 The system ATT is rather complex and its architecture is composed from several modules. Here, we will mention just those functions that are relevant from user’s point of view. The system can process acoustic data that are either stored in previously recorded files or that come directly from on-line sources, such as a microphone, TV/radio card or internet stream broadcasting. The audio data are sampled at 16 kHz rate with 16 bit resolution and stored without any compression to assure the best performance of voice-to-text algorithms. In case of TV shows, the video part is not stored, instead the link to the web source is registered.
The system ATT is rather complex and its architecture is composed from several modules. Here, we will mention just those functions that are relevant from user’s point of view. The system can process acoustic data that are either stored in previously recorded files or that come directly from on-line sources, such as a microphone, TV/radio card or internet stream broadcasting. The audio data are sampled at 16 kHz rate with 16 bit resolution and stored without any compression to assure the best performance of voice-to-text algorithms. In case of TV shows, the video part is not stored, instead the link to the web source is registered.
MyVoice 2.0 (2020) - voice controlled PC tool
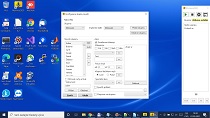 MyVoice 2.0 is primarily designed for voice control of the operating system Microsoft Windows 10. Voice commands allow you to fully replace the keyboard and mouse, which gives mainly people with motor disabilities a chance to participate in every day and working life. The voice recognition engine is maximally adapted to the needs of target users, for whom it is necessary to take a highly variable, sometimes non-standard, pronunciation. In addition to using predefined commands, the program allows you to create new commands that better meet the user's needs.
MyVoice 2.0 is primarily designed for voice control of the operating system Microsoft Windows 10. Voice commands allow you to fully replace the keyboard and mouse, which gives mainly people with motor disabilities a chance to participate in every day and working life. The voice recognition engine is maximally adapted to the needs of target users, for whom it is necessary to take a highly variable, sometimes non-standard, pronunciation. In addition to using predefined commands, the program allows you to create new commands that better meet the user's needs.
MyDictate – program for discrete-speech dictation
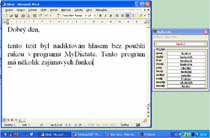 The dictation tool MyDictate was designed to work with discrete-speech input. It can be used as a standalone program or as an extension to the previously developed MyVoice. MyDictate was created for text dictation, which is a slightly different type of PC application. In this case, the active vocabulary must be very large (more than one hundred thousands items). This vocabulary changes only occasionally when the user wants to add a new word.
The dictation tool MyDictate was designed to work with discrete-speech input. It can be used as a standalone program or as an extension to the previously developed MyVoice. MyDictate was created for text dictation, which is a slightly different type of PC application. In this case, the active vocabulary must be very large (more than one hundred thousands items). This vocabulary changes only occasionally when the user wants to add a new word.
Our older projects (1995-2010):
MobilDictate - Very Large Vocabulary Voice Dictation for Mobile Devices
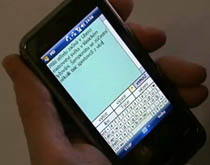 The task we solved was challenging: build a standalone speech recognizer for Czech that would be practically deployable on recent PDAs and smart mobile phones. We had to find a way to manage vocabularies with 250K+ words and make voice input faster than the typing with a stylus (supported by the T9). Our approach employs a discrete speech recognition engine optimized for speed, memory usage and power consumption. Using the touch screen for disambiguation and correction of voice input, we almost eliminate the use of the stylus. The engine has been designed as language independent, though we had in mind Czech users as the first target group. Czech is an inflected language with more than one million distinct word-forms.
The task we solved was challenging: build a standalone speech recognizer for Czech that would be practically deployable on recent PDAs and smart mobile phones. We had to find a way to manage vocabularies with 250K+ words and make voice input faster than the typing with a stylus (supported by the T9). Our approach employs a discrete speech recognition engine optimized for speed, memory usage and power consumption. Using the touch screen for disambiguation and correction of voice input, we almost eliminate the use of the stylus. The engine has been designed as language independent, though we had in mind Czech users as the first target group. Czech is an inflected language with more than one million distinct word-forms.
SmartRoom - Voice Controlled Center for Homes of Motor-Handicapped Persons
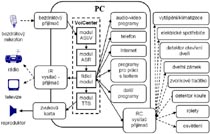 Our SmartRoom was developed like prototype mainly for motor-handicapped people for controlling of PC and electric devices in their homes. Several different ways exist at present how to control PC without hands, but the voice is the most natural way of them. Our system consists from two modules: program MyVoice and unit for controlling external electric devices (program VoiCenter). External devices like, e.g. electric heating, lights or different IR controlled home appliances (TV, Hi-Fi, DVD) are controlled by voice commands.
Our SmartRoom was developed like prototype mainly for motor-handicapped people for controlling of PC and electric devices in their homes. Several different ways exist at present how to control PC without hands, but the voice is the most natural way of them. Our system consists from two modules: program MyVoice and unit for controlling external electric devices (program VoiCenter). External devices like, e.g. electric heating, lights or different IR controlled home appliances (TV, Hi-Fi, DVD) are controlled by voice commands.
MyVoice - voice controlled PC tool
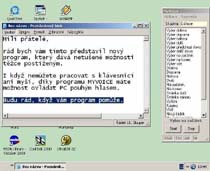 The program named MyVoice was completed in 2005 and since that time, several tens of handicapped users have learned to use it. It allows them to control any application installed on their computers entirely by voice. Any program running under Microsoft Windows OS can be started and controlled by voice commands imitating key-presses and mouse actions. In this way one can utilize an Internet browser, exchange e-mails, draw pictures, listen to music, or type text documents. The tools from MyVoice program are based on a common recognition engine that process the speech signal from a microphone and translates it into events.
The program named MyVoice was completed in 2005 and since that time, several tens of handicapped users have learned to use it. It allows them to control any application installed on their computers entirely by voice. Any program running under Microsoft Windows OS can be started and controlled by voice commands imitating key-presses and mouse actions. In this way one can utilize an Internet browser, exchange e-mails, draw pictures, listen to music, or type text documents. The tools from MyVoice program are based on a common recognition engine that process the speech signal from a microphone and translates it into events.
ProtoATT - prototype of system for automatic transcription of Czech broadcast
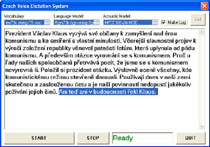
 Automatic spoken documents transcription is a very computation-intensive task. State-of-the-art transcription systems employ Viterbi decoder and Hidden Markov Models, where speed of transcription is strictly determined by: vocabulary size, processor speed and memory bandwidth. Czech language belongs among inflective languages and for good spoken language coverage transcription systems need large vocabularies, which directly decrease transcription speed. There are several possibilities how to accelerate transcription of continuous multimedia stream without decreasing vocabulary size. The first one is parallel Viterbi decoding, that is very hard to implement on current hardware.
Automatic spoken documents transcription is a very computation-intensive task. State-of-the-art transcription systems employ Viterbi decoder and Hidden Markov Models, where speed of transcription is strictly determined by: vocabulary size, processor speed and memory bandwidth. Czech language belongs among inflective languages and for good spoken language coverage transcription systems need large vocabularies, which directly decrease transcription speed. There are several possibilities how to accelerate transcription of continuous multimedia stream without decreasing vocabulary size. The first one is parallel Viterbi decoding, that is very hard to implement on current hardware.
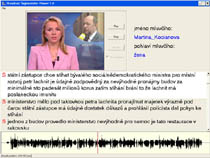
 In 2003, we presented to the professional public a prototype of the first voice dictation system for Czech. Its limitation was that it was necessary to dictate text word for word, always with a short space between words. On the other hand, the system worked with a dictionary containing 400,000 of the most common words and word forms, which is almost 99% of the entire vocabulary of the Czech language. The system also enabled voice-controlled text formatting and editing of misrecognized words.
In 2003, we presented to the professional public a prototype of the first voice dictation system for Czech. Its limitation was that it was necessary to dictate text word for word, always with a short space between words. On the other hand, the system worked with a dictionary containing 400,000 of the most common words and word forms, which is almost 99% of the entire vocabulary of the Czech language. The system also enabled voice-controlled text formatting and editing of misrecognized words.
Dundis - Internet speech recognizer
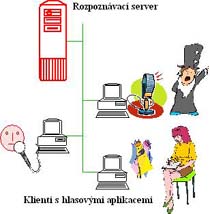 The aim of distributed speech recognition (DSR) is in the fact that user's computer only records speech and DSR server provides speech recognition. Therefore user's computer (client) is unloaded by recognition algorithms that consume lot of computing power and memory. The recognition data are transferred from client to server via Internet. In our lab was developed DSR system with isolated word recognition engine for Czech. The communication between server and clients is based on TCP/IP protocol. The server is designed for mass multiuser usage with power scalability. It is possible to setup up predefined vocabularies (up to million items) and if it is needed to upload user's own vocabulary with limited size (10000 words).
The aim of distributed speech recognition (DSR) is in the fact that user's computer only records speech and DSR server provides speech recognition. Therefore user's computer (client) is unloaded by recognition algorithms that consume lot of computing power and memory. The recognition data are transferred from client to server via Internet. In our lab was developed DSR system with isolated word recognition engine for Czech. The communication between server and clients is based on TCP/IP protocol. The server is designed for mass multiuser usage with power scalability. It is possible to setup up predefined vocabularies (up to million items) and if it is needed to upload user's own vocabulary with limited size (10000 words).
Chatter - The 3-D Artificial Talking Head
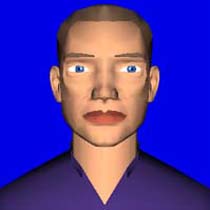 In the Laboratory of computer speech processing in the Technical University of Liberec in the Czech Republic the fully parametric 3-D model of computerized talking head for Czech language has been developed. We call this model “Chatter”. At present we are optimizing parameters of the model for all Czech phonemes (2003). We are planning to use Czech diphones or even triphones collection for the improvement of accuracy of our model in the future. We want to prepare a new test of comprehensibility in the future as well. We want to find how much comprehensible is this model of Czech talking head for Czech people in this test. This model of talking head will be used in our own next multimodal projects in which audio-visual speech synthesis, speech processing, speech recognition...
In the Laboratory of computer speech processing in the Technical University of Liberec in the Czech Republic the fully parametric 3-D model of computerized talking head for Czech language has been developed. We call this model “Chatter”. At present we are optimizing parameters of the model for all Czech phonemes (2003). We are planning to use Czech diphones or even triphones collection for the improvement of accuracy of our model in the future. We want to prepare a new test of comprehensibility in the future as well. We want to find how much comprehensible is this model of Czech talking head for Czech people in this test. This model of talking head will be used in our own next multimodal projects in which audio-visual speech synthesis, speech processing, speech recognition...
ConRec 0.1 - Czech Continuous Speech Recognition in Real Time
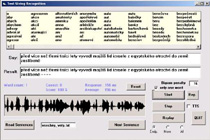 Within this project we have developed the first continuous speech recognition for Czech that can work with a vocabulary containing up to 20 000 most frequent words. We have used several optimization strategies, such as efficient computation of HMM probability densities, pruning schemes applied to HMM states, words and word hypotheses, a bigram compression technique as well as parallel implementation of the real recognition system. On a 2 GHz computer the system can display the recognized text in time leas than 1 s after the end of the utterance. In sentences with no OOV words the recognition rate is about 80 %.
Within this project we have developed the first continuous speech recognition for Czech that can work with a vocabulary containing up to 20 000 most frequent words. We have used several optimization strategies, such as efficient computation of HMM probability densities, pruning schemes applied to HMM states, words and word hypotheses, a bigram compression technique as well as parallel implementation of the real recognition system. On a 2 GHz computer the system can display the recognized text in time leas than 1 s after the end of the utterance. In sentences with no OOV words the recognition rate is about 80 %.
Lotos - Graphic platform for designing and developing practical voice interaction systems
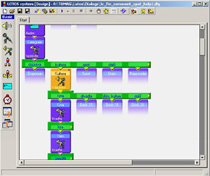 The LOTOS is a development platform for designing, testing and running practical voice operated services, such as automated information systems running over telephone. The LOTOS graphic environment allows for building dialogue schemes using a small set of bricks: an ASR brick, a TTS brick, a question brick (combination of ASR & TTS), a switch node, a database query block and several others. Even a large scheme can be built in very short time simply by placing bricks on the form and specifying their properties. Due to a unique display layout no brick-interconnecting lines are needed and the dialogue design is compact. The LOTOS supports the "active database" approach...
The LOTOS is a development platform for designing, testing and running practical voice operated services, such as automated information systems running over telephone. The LOTOS graphic environment allows for building dialogue schemes using a small set of bricks: an ASR brick, a TTS brick, a question brick (combination of ASR & TTS), a switch node, a database query block and several others. Even a large scheme can be built in very short time simply by placing bricks on the form and specifying their properties. Due to a unique display layout no brick-interconnecting lines are needed and the dialogue design is compact. The LOTOS supports the "active database" approach...
Chat with a Virtual Character-The Švejk Project
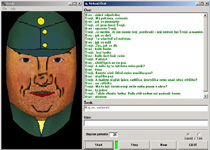 This project has been our initial attempt to link speech processing technology, namely continuous speech recognition, text-to-speech synthesis and artificial talking head, with text processing techniques in order to design a Czech demonstration system that allows for informal voice chatting with virtual characters. Legendary novel figure Svejk is the first personality who can be interviewed in the recently implemented version. It is good for any research if its state-of-the-art can be demonstrated on applications that are attractive not only for a small scientific community but also for wider public. This type of application may go even beyond traditional existing or commercial areas.
This project has been our initial attempt to link speech processing technology, namely continuous speech recognition, text-to-speech synthesis and artificial talking head, with text processing techniques in order to design a Czech demonstration system that allows for informal voice chatting with virtual characters. Legendary novel figure Svejk is the first personality who can be interviewed in the recently implemented version. It is good for any research if its state-of-the-art can be demonstrated on applications that are attractive not only for a small scientific community but also for wider public. This type of application may go even beyond traditional existing or commercial areas.
BALDI (talking head) speaking Czech
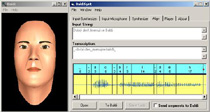 Baldi is a computer animated talking head developed at the University of California at Santa Cruz in late 1990s. Baldi produces realistic animation of face, mouth and tongue movements synchronized with either synthetic or natural speech. Primarily, Baldi was developed as an aid for teaching hearing handicapped children, but it might have much broader scope of usage, e.g. as an animated agent in information kiosks, as a tool supporting perception of synthesized speech...
Baldi is a computer animated talking head developed at the University of California at Santa Cruz in late 1990s. Baldi produces realistic animation of face, mouth and tongue movements synchronized with either synthetic or natural speech. Primarily, Baldi was developed as an aid for teaching hearing handicapped children, but it might have much broader scope of usage, e.g. as an animated agent in information kiosks, as a tool supporting perception of synthesized speech...
INFOCITY - first Czech telephone information system with voice input and output
 The INFOCITY is a working prototype of a telephone information system based on speech dialogue between a user and a computer. In the recent version it offers four major information sections for city of Liberec: culture, sport, transport and others, as it is shown in figure above. The culture section gives an access to programs of cinemas, theaters, clubs, museums, galleries and other cultural establishments. To get the information about the program, the user must specify the place and the day (up to one week ahead). Information on current sport events is available in a similar way. The transport section handles inquiries on city transport (trams and buses, altogether 30 lines)...
The INFOCITY is a working prototype of a telephone information system based on speech dialogue between a user and a computer. In the recent version it offers four major information sections for city of Liberec: culture, sport, transport and others, as it is shown in figure above. The culture section gives an access to programs of cinemas, theaters, clubs, museums, galleries and other cultural establishments. To get the information about the program, the user must specify the place and the day (up to one week ahead). Information on current sport events is available in a similar way. The transport section handles inquiries on city transport (trams and buses, altogether 30 lines)...
VISPER - VIsual SPEech PRocessing System
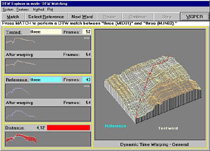 The VISPER is a unique software system designed for education of some essential topics in automatic speech processing. Its main power consists in visualization of the basic tasks associated with speech recognition, such as signal acquisition, speech parameterization, endpoint detection, DTW-based matching or the application of the hidden Markov modeling technique. Learning and understanding these topics becomes much easier with the VISPER because the system is like an experimental workbench that allows a user to search answers on many common questions by experiments.
The VISPER is a unique software system designed for education of some essential topics in automatic speech processing. Its main power consists in visualization of the basic tasks associated with speech recognition, such as signal acquisition, speech parameterization, endpoint detection, DTW-based matching or the application of the hidden Markov modeling technique. Learning and understanding these topics becomes much easier with the VISPER because the system is like an experimental workbench that allows a user to search answers on many common questions by experiments.
VICK (VIsual FeedbaCK) System for Speech Training
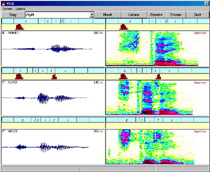 VICK is a visual feedback aid for speech training. It is a PC based speech processing system that visualizes incoming signal and its most relevant parameters (such as volume, pitch, timing, spectrum) and compares them to utterances recorded by reference speakers. The goal is to help a trained person in identifying the most severe deviations in his or her pronunciation. The learning through visual comparison is supported by displaying multiple reference utterances, including phonetic labels both to the reference speakers' and trainee's speech, indicating the areas with larger deviations in any of the displayed features and offering a simple tutoring assessment of the trainee's attempts.
VICK is a visual feedback aid for speech training. It is a PC based speech processing system that visualizes incoming signal and its most relevant parameters (such as volume, pitch, timing, spectrum) and compares them to utterances recorded by reference speakers. The goal is to help a trained person in identifying the most severe deviations in his or her pronunciation. The learning through visual comparison is supported by displaying multiple reference utterances, including phonetic labels both to the reference speakers' and trainee's speech, indicating the areas with larger deviations in any of the displayed features and offering a simple tutoring assessment of the trainee's attempts.
RoboVoice - The Model of Robot Controlled by Voice
 Voice control of robot was developed at SpeechLab in Liberec. The methods of fast and reliable recognition with a noise are tested with this program. There is a big difference between the voice control program operating only in the computer monitor and the voice control program operating with real machines, especially mechanical and moving devices. A model of robot is used for experiments with voice control of mechanical devices. The main investigated problems are elimination of the noise produced by drives, reaction time in real-time control, stress in speech in emergency situations.
Voice control of robot was developed at SpeechLab in Liberec. The methods of fast and reliable recognition with a noise are tested with this program. There is a big difference between the voice control program operating only in the computer monitor and the voice control program operating with real machines, especially mechanical and moving devices. A model of robot is used for experiments with voice control of mechanical devices. The main investigated problems are elimination of the noise produced by drives, reaction time in real-time control, stress in speech in emergency situations.
DeafTeacher - The tool for teaching of deaf people
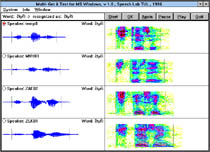 Learning and practising basic speech abilities is an ex-tremely hard task for a deaf person. His or her essential problem consists in the fatal lack of the feedback infor-mation about the produced sounds. For the speech thera-pist involved in the training, the main problem is how to translate the missing acoustic information, whose nature is quite complex, back into a form that would be accept-able and understandable for the trained subject. In order to help both the sides, the deaf and the therapist, we have developed a program that is capable of visual-ising speech signals. The program gets data directly from the microphone and displays them on the computer screen.
Learning and practising basic speech abilities is an ex-tremely hard task for a deaf person. His or her essential problem consists in the fatal lack of the feedback infor-mation about the produced sounds. For the speech thera-pist involved in the training, the main problem is how to translate the missing acoustic information, whose nature is quite complex, back into a form that would be accept-able and understandable for the trained subject. In order to help both the sides, the deaf and the therapist, we have developed a program that is capable of visual-ising speech signals. The program gets data directly from the microphone and displays them on the computer screen.
KeyVoice - Voice instead of Keyboard
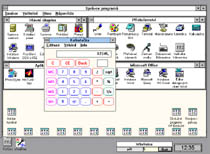 Modern computer systems offer a rapidly growing number of applications and services (for example, telephoning, faxing, controlling devices like radio, TV or home appliences) that might be very helpful, particularly, for people with different kinds of disabilities. Unfortunately, not all of these people can utilize this chance, simply because their handicap does not allow them to use a keyboard or a mouse. For them, a voice controlled computer could be one the most appropriate options. The idea of the voice control developed at our lab differs from those used in similar systems. Instead of designing special new software for the handicaped...
Modern computer systems offer a rapidly growing number of applications and services (for example, telephoning, faxing, controlling devices like radio, TV or home appliences) that might be very helpful, particularly, for people with different kinds of disabilities. Unfortunately, not all of these people can utilize this chance, simply because their handicap does not allow them to use a keyboard or a mouse. For them, a voice controlled computer could be one the most appropriate options. The idea of the voice control developed at our lab differs from those used in similar systems. Instead of designing special new software for the handicaped...
VoiceGame - Voice Controlled Games and Tools for Handicaped Children
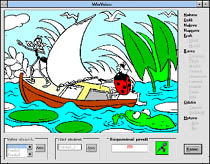 We have developed several tools and games that can be used by handicaped users, particularly, by children. The games, like a tile-moving mosaic or a fill-colour painting sheet - shown above, are controlled entirely by voice, giving thus a chance to those who - from various reasons - cannot use keyboard and mouse. Some of the games and tools have got facilities allowing them to be utilized as training (as well as motivating) aids for teaching hearing-impaired people. These facilities have been designed to give a disabled user a visual feedback on the quality of his/her speech. It is achieved by visualizing the speech waveform and its spectrum, and comparing them to those of reference speakers.
We have developed several tools and games that can be used by handicaped users, particularly, by children. The games, like a tile-moving mosaic or a fill-colour painting sheet - shown above, are controlled entirely by voice, giving thus a chance to those who - from various reasons - cannot use keyboard and mouse. Some of the games and tools have got facilities allowing them to be utilized as training (as well as motivating) aids for teaching hearing-impaired people. These facilities have been designed to give a disabled user a visual feedback on the quality of his/her speech. It is achieved by visualizing the speech waveform and its spectrum, and comparing them to those of reference speakers.
InfoBus - Dialog with Computer
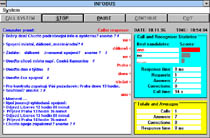 The system, hosted by a personal computer, includes a speech producing unit, a discrete-utterance recogniser and a manager that controls the communication between the computer and a user. Information exchange consists in a spoken dialogue, which is - from practical reasons - driven by the system according to the given scenario. In the currently developed version, the system offers information about bus departures from Liberec bus station. To learn the requested piece of information, the user must answer several questions about the destination, day and approximate time of his/her journey.
The system, hosted by a personal computer, includes a speech producing unit, a discrete-utterance recogniser and a manager that controls the communication between the computer and a user. Information exchange consists in a spoken dialogue, which is - from practical reasons - driven by the system according to the given scenario. In the currently developed version, the system offers information about bus departures from Liberec bus station. To learn the requested piece of information, the user must answer several questions about the destination, day and approximate time of his/her journey.
VoiceCAD - a simple voice controlled drawing system
 What you see on the screen has been drawn by means of VoiceCAD, a simple system for demonstrating voice command controlled tools. The system employed a speaker-independent isolated-word recogniser and was based on the application of continuous density hidden Markov models (HMM). The system was developed in 1994 as a demostration tool and that time run on a PC (386/33) in real time.
What you see on the screen has been drawn by means of VoiceCAD, a simple system for demonstrating voice command controlled tools. The system employed a speaker-independent isolated-word recogniser and was based on the application of continuous density hidden Markov models (HMM). The system was developed in 1994 as a demostration tool and that time run on a PC (386/33) in real time.